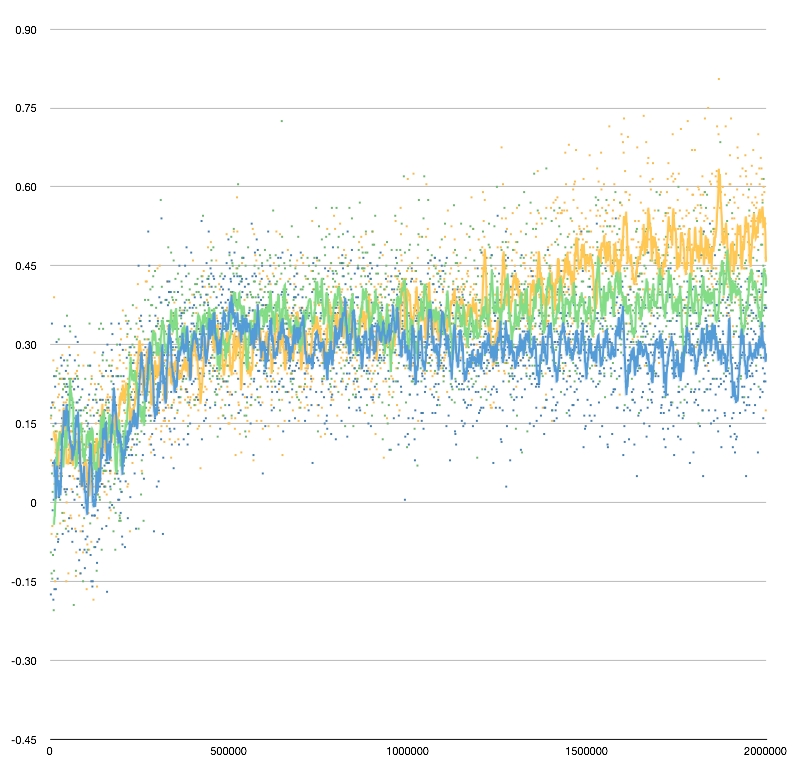
The first network I set up had just one output node, which represents the probability of a win - any kind of win, ignoring the distinction between single wins and gammons/backgammons.
This was a simplification of the original Tesauro work which had four outputs: one for a win, one for a gammon win, one for a loss, and one for a gammon loss. There was no knowledge in the network of backgammons, under the assumption that in practice they happen so rarely that they can be ignored (this is true in regular games between experienced human players).
So the next step in the evolution of my net is to add an understanding of gammons. As with the single-output network, I want the network to do the right thing when you flip the perspective of a board and pass it in. For a multi-output network this means that prob of win->prob of loss, prob of gammon win->prob of gammon loss, and so on.