The earlier work was not in vain: I generalized the network so that they do not make the symmetry assumptions, but used the symmetry network weights as starting points for the training of the generic networks. That allowed relatively fast training.

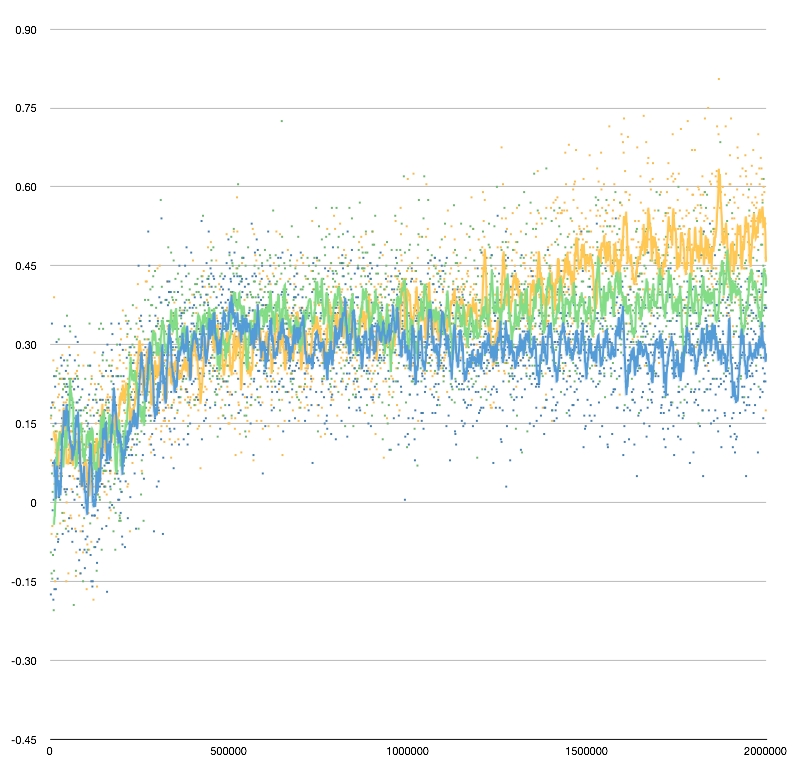
Here are some results showing the training performance for 20-, 40-, and 80-hidden node networks:

The training worked as before, except that the benchmark was no longer the pubEval player, as that was too weak for sensible comparisons. Instead, each generic network used the maximal-performance version of the symmetric network with the same number of hidden nodes as a benchmark. So for example, the 80-hidden node training used the 80-hidden node version of the symmetric network as a benchmark - and used the instance of that symmetric network that performed best against the pubEval benchmark in its training.
In all cases the trained networks performed around +0.2-0.3ppg vs their benchmarks, and in the maximal cases got to about +0.4-0.5ppg. (In the 200-game comparison runs done every 1,000 training iterations.)
In all cases the trained networks performed around +0.2-0.3ppg vs their benchmarks, and in the maximal cases got to about +0.4-0.5ppg. (In the 200-game comparison runs done every 1,000 training iterations.)
These results show that the training does continue to improve the performance of the bots, even without adding a separate race network. However, there are some mysteries that I am still trying to decipher:
- At each training step, I have to train it against the board and its flipped-perspective board. That makes sense for the final step where you use the actual win or lose performance at the end of the game, since otherwise you would never train the probability-of-gammon-loss node (since the update function is called only from the perspective of the winner, since that is the last play in any game). But I do not understand why the training fails to work if I do not train it on the flipped board for every step.
- The network should know which player holds the dice. As mentioned before, this is key to knowing the probability of winning or losing at every point, and especially at some end game scenarios. I tried adding a new input which is 1 if the player holds the dice, and 0 otherwise; and initialized the weights for those inputs to zero. However, the training fails if I actually train those weights. The results above do not train these weights.
"Training fails" above means that the weights become large and positive for the probability of win and probability of gammon win nodes, and large and negative for the probability of gammon loss node. And of course the measured performance of the network vs its benchmark is terrible.
I am not sure why this is happening, and I want to sort that out before I move on to adding a separate race network.