I turned off backtracking and alpha/beta decay, since that seemed to have minimal effect in my previous experiments. I also dropped alpha and beta to 0.1 to avoid jumping around too much.
Then I let the training run for 2M iterations to see if I could get something that is plausibly converged. Honestly I don't even know if a realistic neural net does converge, but looking at other articles on TD gammon training it looks like they do.
Here are the results:

The blue line and blue points are for a network with 10 hidden nodes; green is 20; and orange is 40. The points are the average points per game playing the network against the pubEval benchmark for 200 games. The lines are the rolling 10-point averages.
Some interesting points:
This is meant to be something like the chart from the TD gammon scholarpedia page:

This goes out to 20M iterations, so is much longer than my 2M runs. But curiously, my networks all do much better than the results above. Even my 10-hidden-node network gets up to +0.3ppg on average.
There are two possibilities here I think: my pubEval player is implemented incorrectly and so is not as good as the player in the scholarpedia chart; or my trick to reduce the number of weights by (roughly) half is actually a new trick that makes convergence easier.
I hope it's the second, but really it's probably the first. So I'll go back and check out the pubEval code.
Regardless of what I find there, though, it is really satisfying to see my neural network actually learning and getting better! I'll have to play a few games against it to get an independent feel now of how well it is playing.
Note: it was the first, of course - my pubEval implementation was buggy. After fixing it's a much stronger player. I also had some significant problems with my network setup. Check out the Jan 2012 posts to see believable results.
Then I let the training run for 2M iterations to see if I could get something that is plausibly converged. Honestly I don't even know if a realistic neural net does converge, but looking at other articles on TD gammon training it looks like they do.
Here are the results:
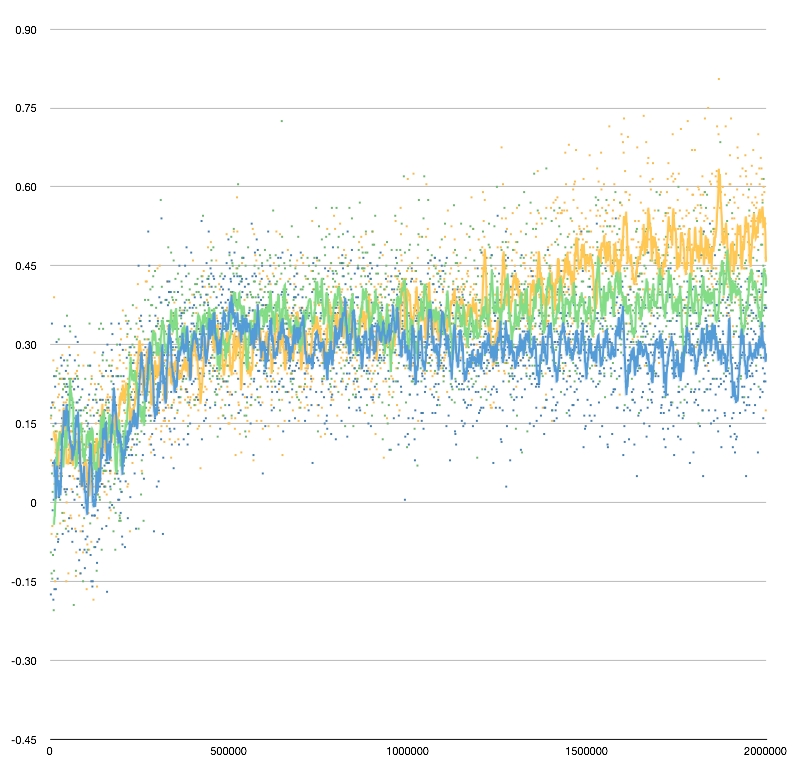
The blue line and blue points are for a network with 10 hidden nodes; green is 20; and orange is 40. The points are the average points per game playing the network against the pubEval benchmark for 200 games. The lines are the rolling 10-point averages.
Some interesting points:
- All three networks improve to about the same point, about as quickly, by around 500k iterations.
- The 10-hidden-node network doesn't get any better, and ends up performing at around +0.3ppg vs pubeval.
- The 20-node network starts to improve again around the 1.2M iteration point, and may still be getting slowly better at the end of the 2M runs, where it plays around +0.38ppg against pubEval.
- The 40-node network also picks up at around 1.2M, and gets considerably better. It still seems to be improving substantially at the end of 2M, where it plays around +0.5ppg against pubEval. Its best games are north of +0.7ppg.
This is meant to be something like the chart from the TD gammon scholarpedia page:

This goes out to 20M iterations, so is much longer than my 2M runs. But curiously, my networks all do much better than the results above. Even my 10-hidden-node network gets up to +0.3ppg on average.
There are two possibilities here I think: my pubEval player is implemented incorrectly and so is not as good as the player in the scholarpedia chart; or my trick to reduce the number of weights by (roughly) half is actually a new trick that makes convergence easier.
I hope it's the second, but really it's probably the first. So I'll go back and check out the pubEval code.
Regardless of what I find there, though, it is really satisfying to see my neural network actually learning and getting better! I'll have to play a few games against it to get an independent feel now of how well it is playing.
Note: it was the first, of course - my pubEval implementation was buggy. After fixing it's a much stronger player. I also had some significant problems with my network setup. Check out the Jan 2012 posts to see believable results.
No comments:
Post a Comment