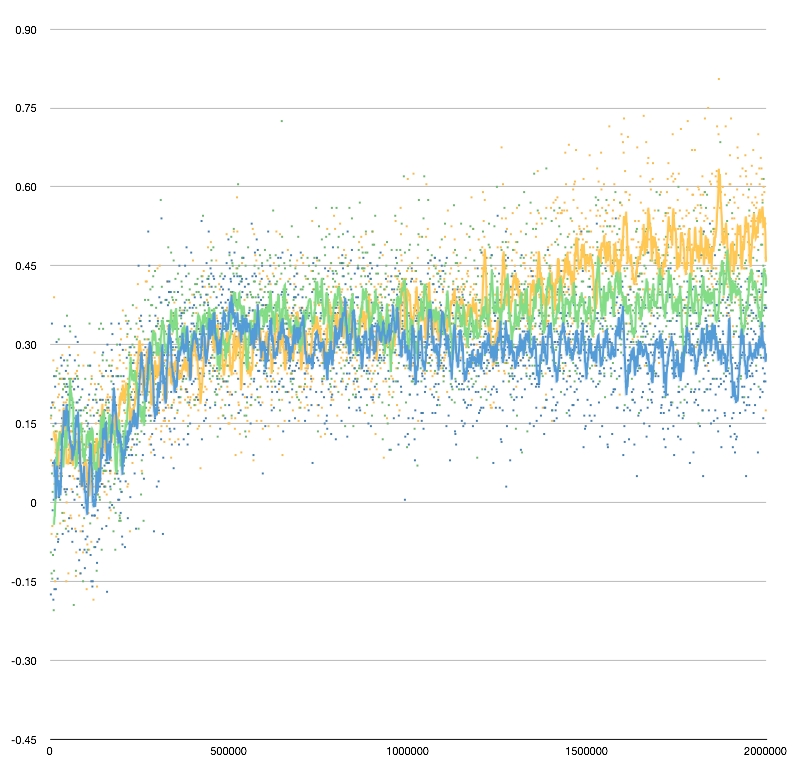
I ran the test described in the previous post out to 400k training runs, and the results were relatively unchanged. In head to head competitions the Normal network started to edge out the Symmetric one, and they started to comparably against the pub eval benchmark, with Symmetric still performing a little better on average.
However, I did some more granular benchmarking and Symmetric did much worse. I looked at the network estimate of probability of win from a pair of end games: one where white is almost sure to win, and one where white is almost sure to lose. Both networks started out estimating both probabilities near 50%, as expected with random weights. But the Normal network over time correctly identified the near-certain win and loss fairly accurately after some tens of thousands of training runs, and the Symmetric network did not. In the certain-to-win case it converged to around 97.5% chance of win, so not far off (but should be very close to 100%); but in the certain-to-lose case it converged to around 20% chance of win, which is way off.
Also, I spent some more time thinking about the basic implications of the Symmetric constraint on the hidden->input weights. In particular: the network probability estimates can ever only depend on the difference between the white and black layouts, not on either one independently. That does not seem to afford sufficient flexibility high-level to the network in making probability estimates.
There might be other ways to enforce the symmetry constraint, but at this point I'm just going to drop the whole thing and follow the same approach as GNU backgammon: always evaluate the board from the perspective of the person holding the dice, and drop the input that represents whose turn it is.
However, I did some more granular benchmarking and Symmetric did much worse. I looked at the network estimate of probability of win from a pair of end games: one where white is almost sure to win, and one where white is almost sure to lose. Both networks started out estimating both probabilities near 50%, as expected with random weights. But the Normal network over time correctly identified the near-certain win and loss fairly accurately after some tens of thousands of training runs, and the Symmetric network did not. In the certain-to-win case it converged to around 97.5% chance of win, so not far off (but should be very close to 100%); but in the certain-to-lose case it converged to around 20% chance of win, which is way off.
Also, I spent some more time thinking about the basic implications of the Symmetric constraint on the hidden->input weights. In particular: the network probability estimates can ever only depend on the difference between the white and black layouts, not on either one independently. That does not seem to afford sufficient flexibility high-level to the network in making probability estimates.
There might be other ways to enforce the symmetry constraint, but at this point I'm just going to drop the whole thing and follow the same approach as GNU backgammon: always evaluate the board from the perspective of the person holding the dice, and drop the input that represents whose turn it is.